

Heyy !!
This article will walk us through how we can make you the first Machine Learning model, and we will also cover the 7 steps involved starting from preparing data to training mode.
Here we will train a Machine learning model with libraries like pandas, seaborn, sklearn, numpy to predict how many medals a country can predict based on their past performance. So sounds exciting???
Let's get started
So what are those 7 steps, well here is an overview ->
Form a Hypothesis
So according to our model, we will say that we can predict how many medals a country is going to win in the Olympics, based on their past performance
Find the data
Now to do so we need data for many two things, the first one being training our model and the second being testing how accurately our model is able to predict the medals
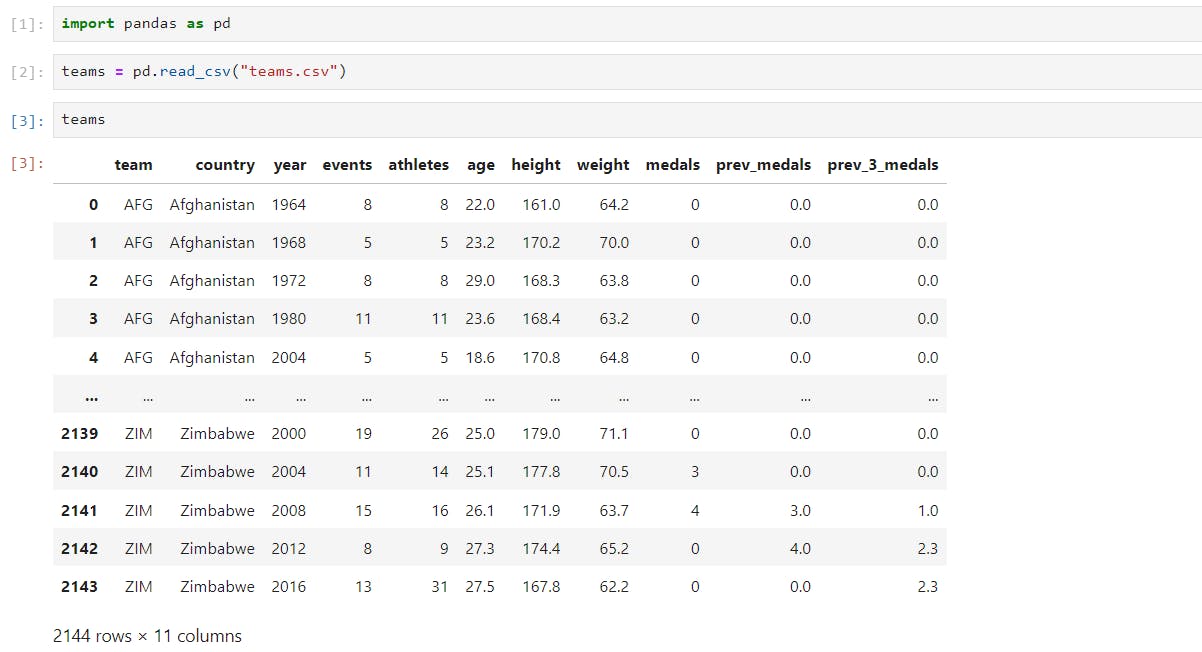
Our data is in CSV format and it contains columns like Country, Year, Athletes, Previous Medals, Current Medals
Reshape the data
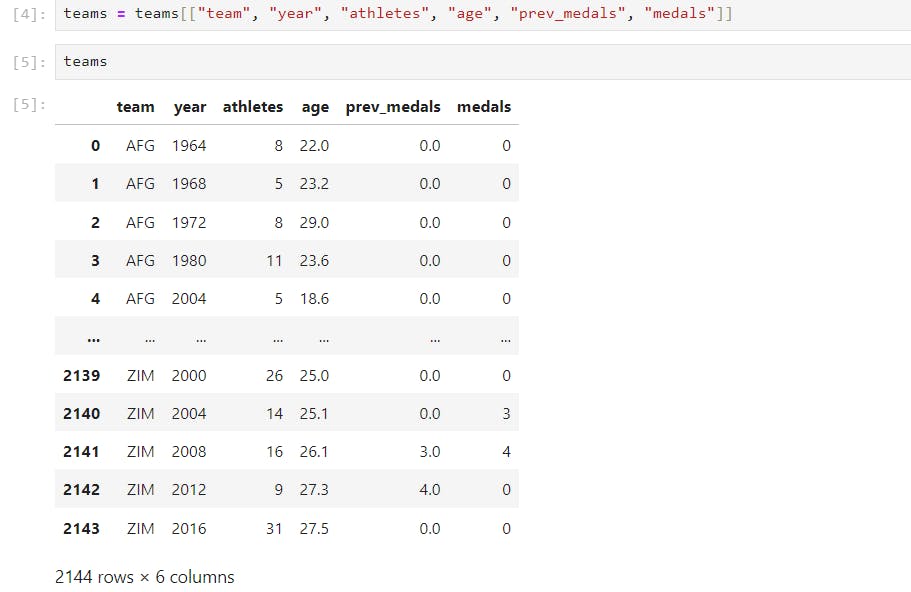
Now we have a data set, we need to reshape it to make ML model predictions Here we are going to predict the final column, the medals column and we are using the athletes and the previous medals column to do that
But why these two columns only ???
Well if we see these two have the highest dependencies on the count of medals won by a country
Factors like the Age of the Athlete do not have a major role to play as we can see from our data
Clean the Data
Now we have the data reshaped, we have to clean the Data, and cleaning the data means(that our data is ready to be used by our ML model), making sure that there are no null columns(or values unavailable) as we know most machine learning algo can't work with missing data.

Error Metric,
We have to evaluate the performance of our ML model so we need to have some kind of measure to let us know how close or off we are from our accurate answer Here the error matrix we are using is called mean absolute error (trust me it's more simple that what it sounds like)
Error = Math.abs(Medals - predicted medals)
So then we add up all the error values and divide them by the total number of predictions we made.

Split the data
As we want to train data on one part of the total data(around 80%) and we want to test the model on another part of the data(around 20%)
Train the model
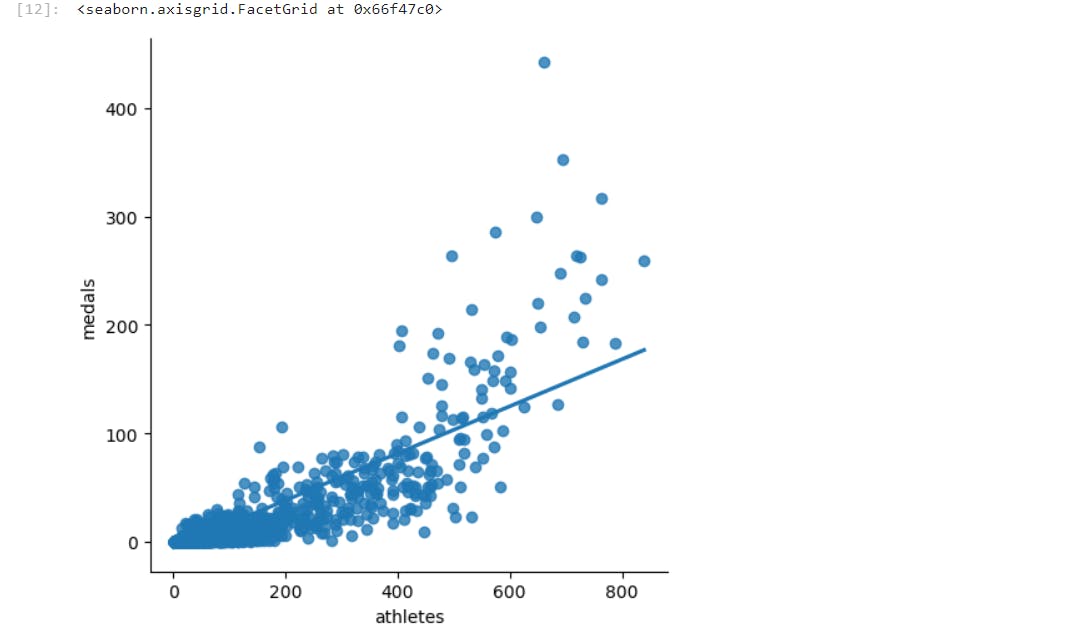
Here we are using liner regressing Y = ax + B--> Uni variant or single variable liner regression y -> Medals last Olympics x -> medals
So a liner regression model will draw a line between the data points on the graph and we can use it to make predictions
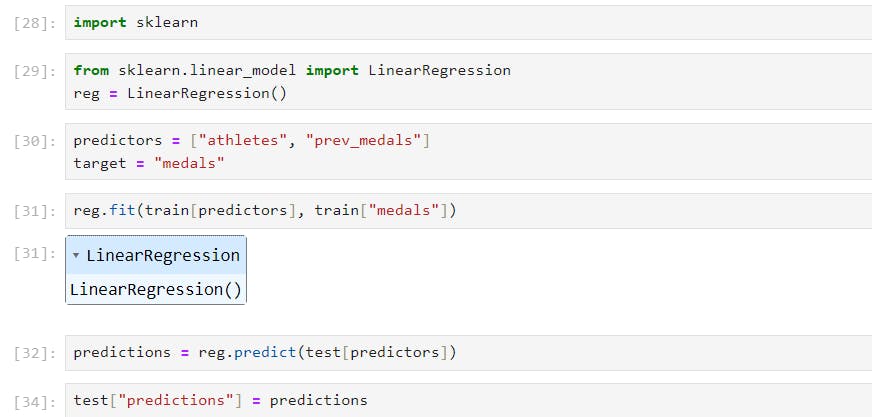
For our model we will be using We are actually going to use two predictors Y = a1x1 + a2x2 + B, as we are considering factors like the number of athletes and the previous medals won by the country
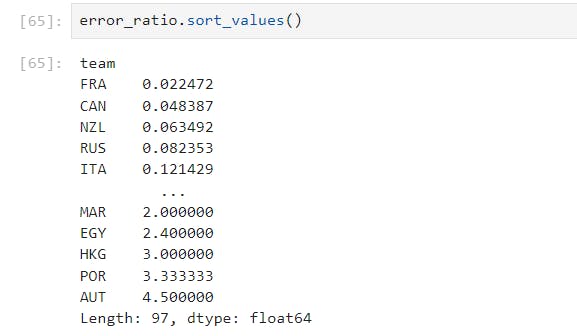
So from our final Output, we can see that our model is more accurate in predicting medals for the country with more medals, however for a country with less medal count our model is not very accurate
I will also provide a link for the whole code file and the dataset used in this project.
Here is the git hub link for the repository -> link
Hope it adds some value : )